Severity Gates: The Missing Layer in AI Agent Workflows
AI agents produce output fast. Code, design documents, API schemas, migration plans — the generation part is solved. The problem is what happens next.
How do you know the output is correct?
Most teams answer this with more context. Longer prompts. More rules. The assumption: if the agent had enough instructions, it would get it right the first time. In practice, the opposite happens. More context means agents forget things. Rules get lost in long sessions. The agent follows 90% of the instructions and silently drops the rest.
But the AI is only half the problem. The human directing the agent might be making wrong decisions — and without something pushing back, those decisions get implemented faithfully.
The trust problem has two sides. AI forgets rules. Humans make wrong calls. Neither side alone is reliable. I wrote about why trust became the expensive part of AI-assisted development — this article is about the methodology to build that trust.
The Core Idea: Severity as Exit Criteria
In 1976, Michael Fagan at IBM applied manufacturing quality control to software. His insight: classify defects by severity, use severity to gate progress.
- Major defect — compromises functional integrity. You cannot proceed.
- Minor defect — stylistic, cosmetic. You can proceed.
That’s it. A binary gate based on severity classification. Not a judgment call. Not “looks good to me.” A deterministic decision: are there unresolved critical issues? Yes → stop. No → continue.
Fagan inspections caught 80-90% of defects. But the full process — planning, group inspection, rework, follow-up — cost 16-20 hours per 1,000 lines of code. Too slow for modern development.
The insight survived. The process didn’t.
How Others Apply This Principle
The same idea — severity drives the verdict — shows up across the industry. Different implementations, same core.
| System | How it gates | Key mechanism |
|---|---|---|
| Google Critique | Severity labels on every comment: Critical (blocks), Nit (non-blocking), Optional, FYI | LGTM depends on resolving all Critical comments. The prefix removes ambiguity |
| Stripe Blueprints | Deterministic nodes + agentic nodes in a pipeline | Agent cannot proceed past a failing deterministic check. 1,300+ PRs/week, all gated |
| Meta Coordinator | Specialized sub-agents review independently, coordinator consolidates | 90-95% convergence threshold. Forces agents to trace code paths before submitting findings |
| CodeRabbit | Two-loop architecture: fast summarization → deep reasoning | 40+ static analysis tools feed into frontier model reasoning. Sandboxed execution |
Two patterns stand out:
- Stripe constrains context aggressively. 400+ internal tools available, but each agent gets only ~15 relevant ones. Less context, more focus. The opposite of “give it everything and hope it remembers.”
- Meta forces justification. Semi-formal reasoning requires agents to state premises, trace paths, and provide conclusions before submitting. This reduces hallucinated findings.
Three Frameworks That Complete the Picture
Severity-gated review judges the output. But a complete evaluation system also needs structure, adversarial pressure, and a technique for surfacing hidden risks.
| Framework | Origin | What it adds |
|---|---|---|
| Stage-Gate | Robert Cooper, 1990. Product development at P&G, 3M, LEGO | Structure. Work happens in phases. Each phase produces an artifact. A gate evaluates: Go / Kill / Hold / Recycle. “Recycle” = iterate |
| Red Team | US Army, 1960s. Adopted in cybersecurity, chaos engineering | Adversarial posture. The evaluator tries to break the plan. Looks for unvalidated assumptions, undiscussed failure modes, dismissed edge cases |
| Pre-mortem | Gary Klein, 2007. Harvard Business Review | Prospective hindsight. “Assume this project failed. Why?” Increases risk identification by 30% vs standard brainstorming. Gives permission to criticize |
Combined:
Stage-Gate provides the when (checkpoints between phases). Red Team provides the how (adversarial, not friendly). Pre-mortem provides the lens (“this shipped and broke — why?”).
The result is not a checklist review. It’s a structured challenge that surfaces what you missed.
The Working Framework
Taking Fagan’s principle (severity as exit criteria) and the orchestration patterns from Google, Stripe, and Meta (multi-reviewer consolidation):
Severity Levels
| Severity | Meaning | Examples |
|---|---|---|
| CRITICAL | Blocks progress | Security risk, data loss, breaking change without migration, business rule violation |
| MAJOR | Must fix, but not a design blocker | Convention violation, missing masking, unsafe migration, missing deprecation plan |
| MINOR | Address during implementation | Naming suggestion, optimization opportunity, documentation gap |
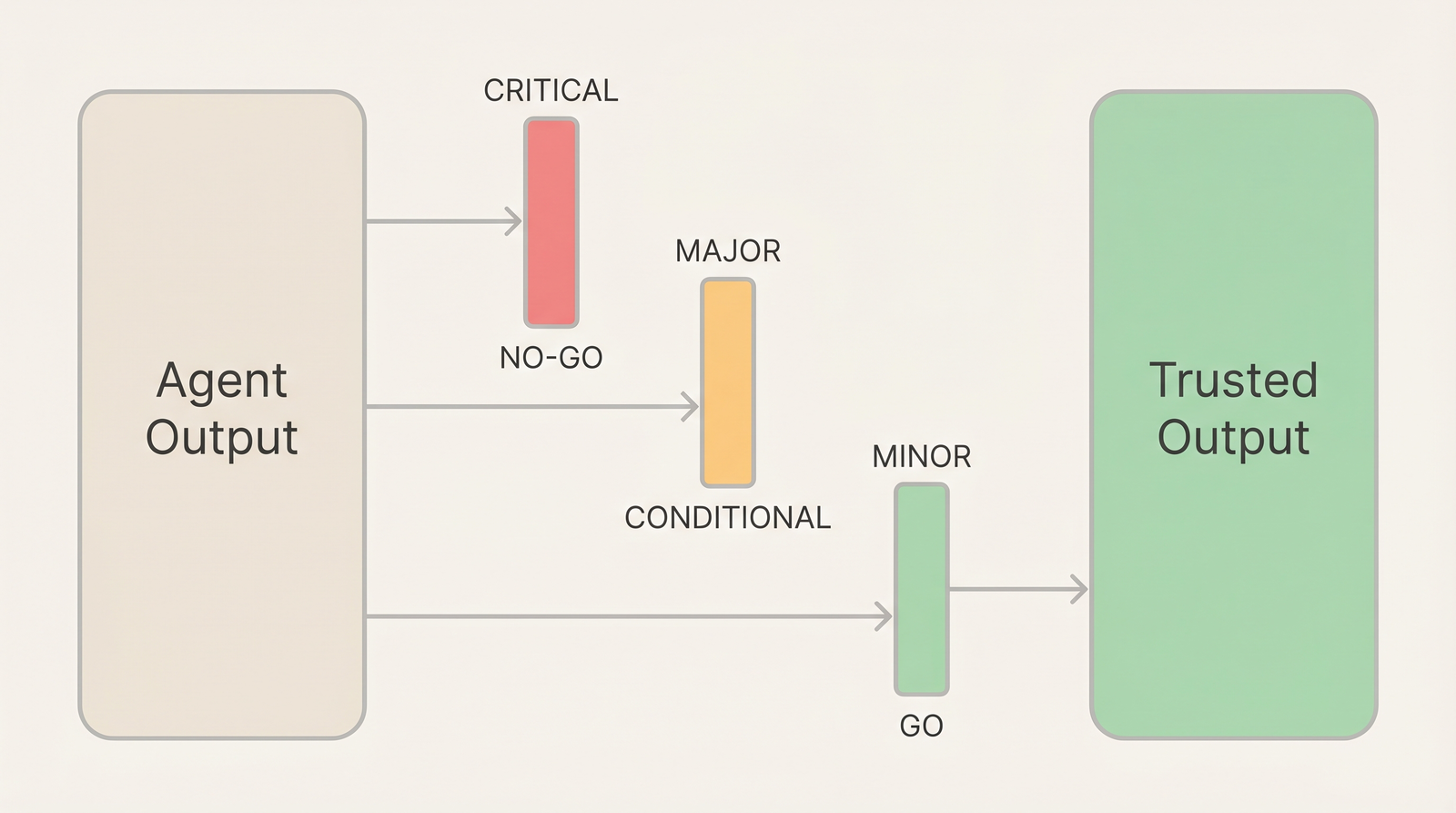
Verdict
Deterministic. No judgment calls.
| Verdict | Condition | Next action |
|---|---|---|
| NO-GO | Any CRITICAL unresolved | Fix CRITICALs, re-run full review |
| CONDITIONAL | No CRITICALs, MAJORs remain | Fix MAJORs, re-run affected reviewer(s) |
| GO | Only MINORs or clean | Proceed |
Structured Findings
Every finding follows the same format:
[SEVERITY] Description
→ Location: file or section affected
→ Action: what to fix or decide
→ Verify: how to confirm the fix is correctThe Verify line is concrete. Not “check it works” but “run X and confirm Y” or “search for Z and verify no references remain.” Actionable without interpretation.
Multi-Agent Orchestration
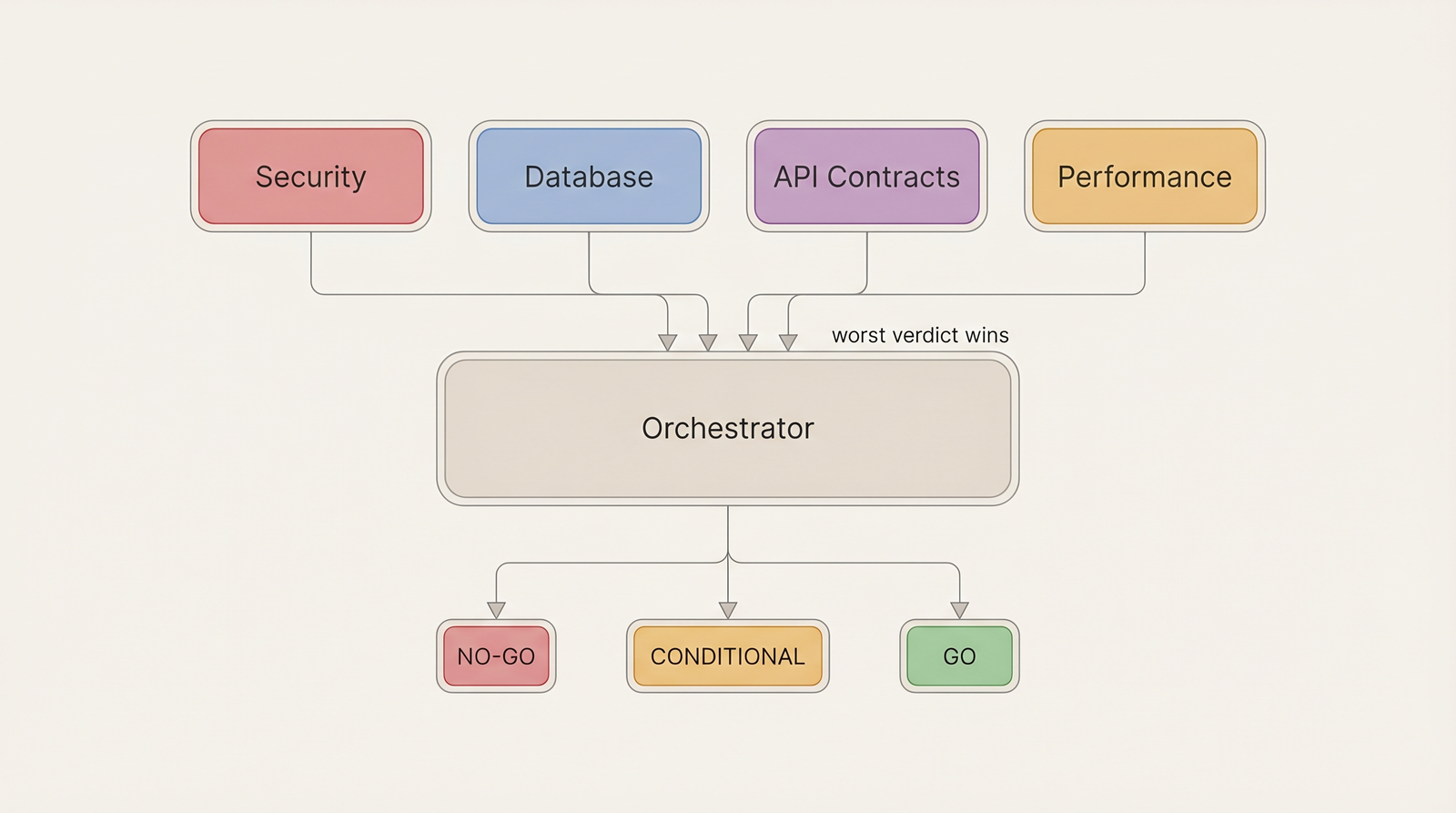
Multiple specialized reviewers (security, database, API contracts, performance) evaluate the same artifact independently. An orchestrator consolidates the results.
Consolidation rule: the final verdict is the worst across all reviewers.
- Any NO-GO → consolidated NO-GO
- Any CONDITIONAL (no NO-GO) → consolidated CONDITIONAL
- All GO → consolidated GO
Each reviewer stays within its domain. The security reviewer doesn’t comment on naming. The database reviewer doesn’t flag API design. Scope boundaries prevent context dilution.
Humans make final decisions. Reviewers surface concerns. They never approve or reject.
The framework defines what to evaluate and how to classify it. For how to wire automated checks into the agent’s working loop — linters after each edit, type checkers incrementally, tests before task completion — see Harness Engineering. The harness is the runtime enforcement. The severity gate is the judgment layer on top.
Gates for Planning, Not Just Code
The highest-value gate is not on the pull request. It’s on the plan.
Fixing a wrong decision in a design document costs minutes. Fixing it after implementation costs days — sometimes weeks, if other features built on top of it. When agents can implement a feature overnight, a wrong decision in the spec becomes wrong code by morning.
The review framework applies to any artifact:
- System design — module boundaries, data flows, dependency direction
- API contracts — backward compatibility, schema breaking changes
- Migration plans — rollback strategy, step ordering, data safety
- Task specs — scope clarity, enough detail for unsupervised execution
Many of these checks can be automated as fitness functions — automated tests that protect structural properties. “No cross-module imports,” “API schema changes must not break clients,” “dependencies flow in one direction.” When a fitness function fails, it becomes a finding in the severity-gated review.
This is where the frameworks connect:
Stage-Gate structures the design into phases. Red Team challenges the design at each gate. Severity-gated review classifies what the challenge finds.
Review the thinking before you review the code. The expensive mistakes are never syntax errors. They are wrong decisions that got implemented correctly.
The Day-Night Shift
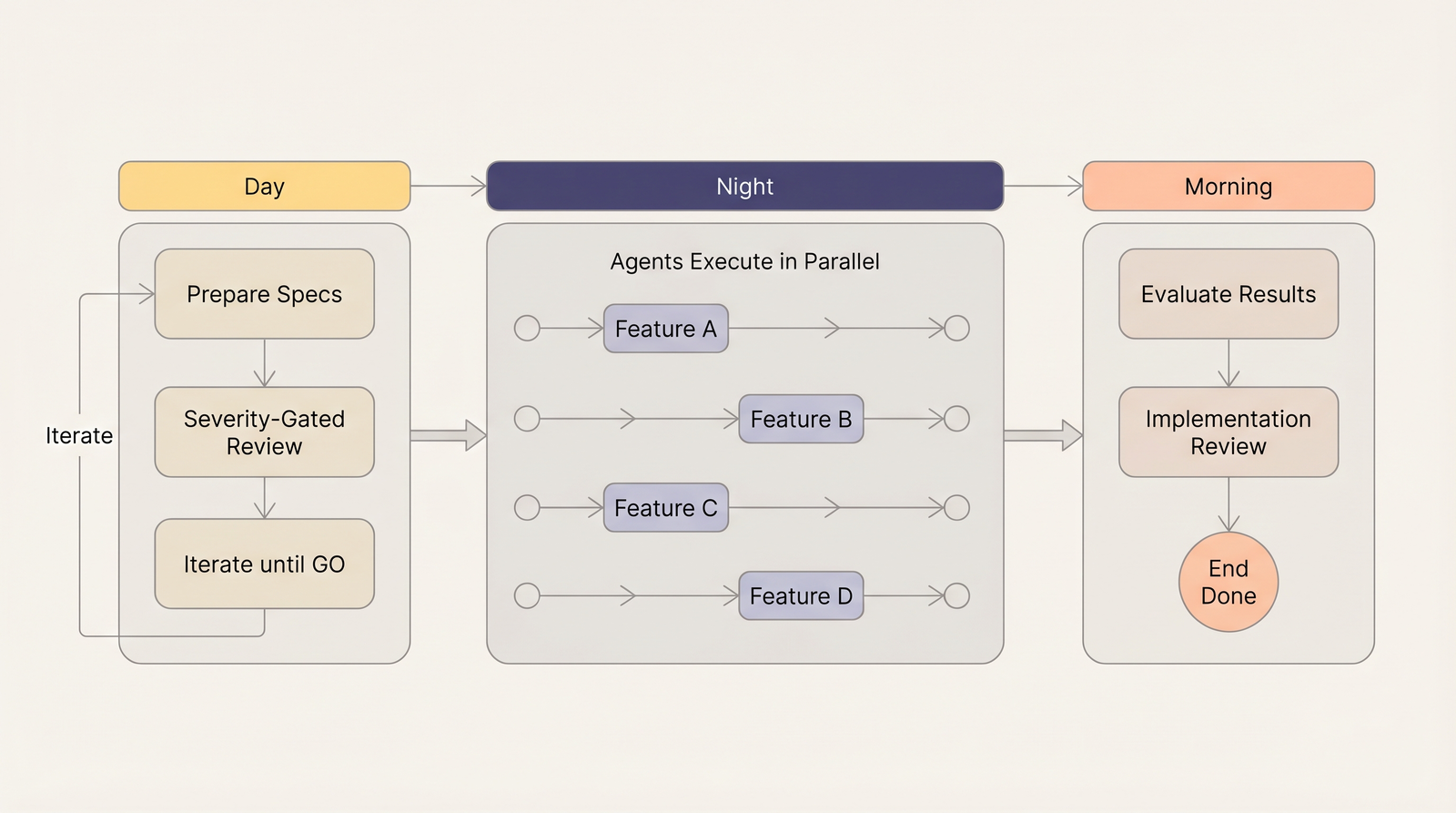
This framework enables a workflow that would be impossible without structured trust in planning output.
Day: Engineers prepare specifications. Design documents go through severity-gated review. Adversarial interrogation challenges assumptions. Iterate until the verdict is GO.
Night: Agents execute. Multiple features in parallel. Each works from a reviewed specification. No supervision needed — the planning has been stress-tested.
Morning: Engineers evaluate results. Implementation review checks that code follows the contracts in the spec. Module boundaries respected? API matches schema? Tests cover the defined behavior?
The day-night shift only works when planning output is trusted enough for unsupervised execution. The review framework creates that trust.
Running 10 features in parallel overnight instead of 1 with constant supervision — that is the unlock. But it requires a structured evaluation layer that most teams don’t have.
The Methodology Is Not New
Fagan solved this in 1976. What changed is the volume. AI agents generate more artifacts, faster, across more domains. The need for structured evaluation didn’t decrease — it increased.
More context doesn’t make agents reliable. Structured evaluation does. The answer to “how do I trust AI output” is not a better prompt. It’s a better gate.
References
- Design Inspections to Reduce Errors in Program Development — Michael Fagan, IBM Systems Journal, 1976. The original severity-classified inspection methodology.
- Winning at New Products — Robert Cooper, 1990. Stage-Gate framework for phased development with decision gates.
- Performing a Project Pre-Mortem — Gary Klein, Harvard Business Review, 2007. Prospective hindsight for risk identification.
- Minions: Stripe’s One-Shot, End-to-End Coding Agents — Stripe Engineering. Blueprint architecture with deterministic and agentic nodes.
- Modern Code Review: A Case Study at Google — Sadowski et al., ICSE 2018. How Google’s Critique system standardizes review severity.