Harness Engineering: When the Fix Is Not a Better Prompt

When an AI agent writes bad code, most people rewrite the prompt. Better instructions. More context. Longer rules files.
Sometimes that works. But more often, the problem is not what the agent was told. The problem is that nothing checked the output.
Agent = Model + Harness
An AI coding agent is two things: the model and the harness.
The model is the AI — the part that generates code. The harness is everything around it — the rules it reads, the checks that run when it acts, the guardrails that prevent damage.
When the output is wrong, the instinct is to fix the model side. Better prompt. More instructions. That’s one lever. But it is not the only lever, and it is often not the right one.
When an agent produces bad output, the fix is almost never a better prompt. It’s a better harness.
Two Sides: Guides and Sensors
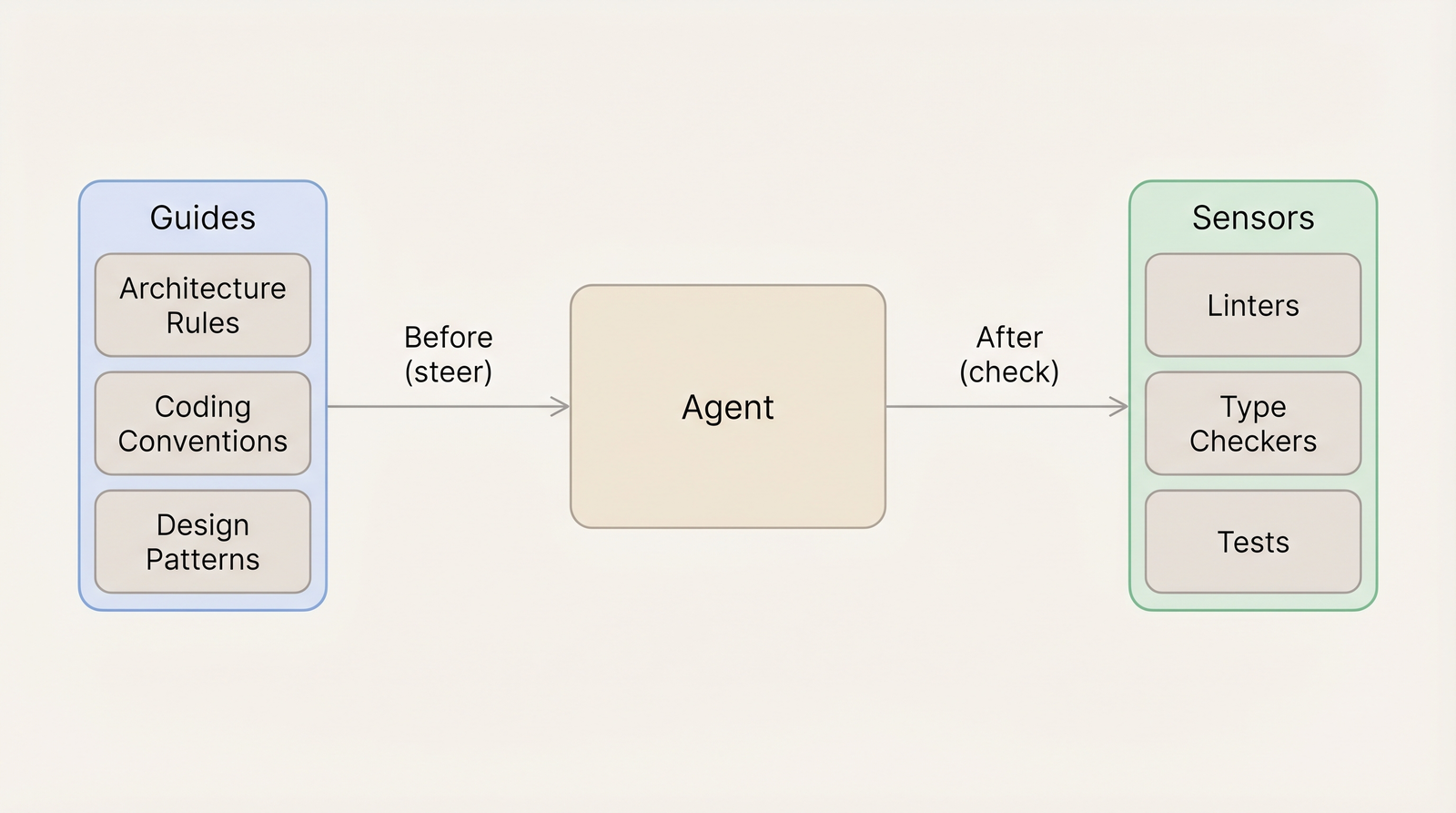
The harness has two sides.
Guides steer the agent before it acts. Architecture rules, coding conventions, design patterns, examples. These are context. Good guides mean the agent writes correctly the first time.
Sensors check the agent after it acts. Linters, type checkers, tests, structural validations. These are verification. Good sensors mean mistakes are caught and corrected automatically — without a human reading the code.
Most teams invest heavily in guides. Rule files, project instructions, architecture documentation. This is the right instinct. But almost nobody has wired sensors into the agent’s working loop.
The tools to catch mistakes already exist in most repositories. Linters, type checkers, test suites — they run in CI. They just aren’t connected to the agent’s feedback cycle.
Here’s what the gap looks like in practice. An agent edits a file and introduces an import that crosses a module boundary. Nothing tells it. It moves on, writes three more files that depend on the broken import. Two hours later, a human reviewer catches the violation. Now four files need to change instead of one.
With sensors wired in, the linter fires after the first edit. The agent sees the boundary violation immediately. It fixes the import before writing the next file. The reviewer never sees the mistake. The fastest feedback loop is the one that doesn’t need a human.
Different moments in the workflow need different sensors:
| When | What runs | Purpose |
|---|---|---|
| After each file edit | Linter (single file, cached) + type checker (incremental) | Catch violations immediately. The agent self-corrects before the next edit |
| When the agent finishes a task | Linter + type checker + related tests | Comprehensive check before a human sees the output |
| Before dangerous commands | Pattern matching on the command | Block force pushes, destructive database operations, production access |
The per-edit sensor needs to be fast — under 5 seconds, or the agent feels slow and engineers disable it. The end-of-task sensor can take longer because it runs once. The safety sensor is just pattern matching — near instant.
The Escalation Ladder
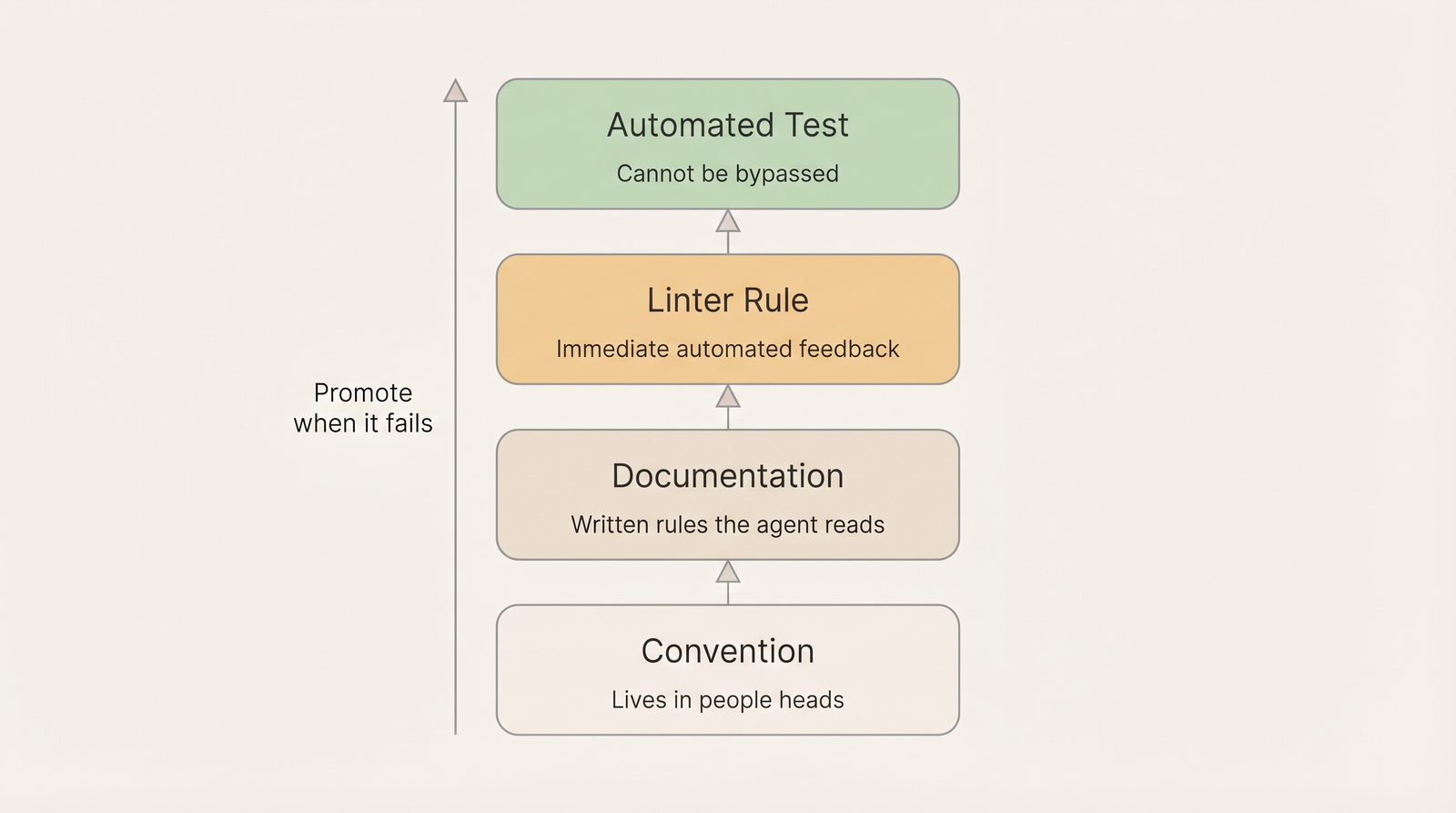
Not every rule needs the same level of enforcement. Rules exist at different levels. When a rule fails repeatedly at one level, it should move to the next.
| Level | How it works | Weakness |
|---|---|---|
| Convention | ”We do it this way.” Lives in people’s heads | Invisible to AI. Breaks silently |
| Documentation | Written in rule files the agent reads | Works most of the time. Can be lost in long sessions |
| Linter rule | Encoded in the tooling. Immediate feedback | Limited to what static analysis can express |
| Automated test | Fails in CI and in the agent’s loop | Can’t be bypassed. Protects the invariant permanently |
When documentation fails to prevent a mistake, promote the rule into code.
A concrete example: “use the repository pattern for database access” starts as documentation. The agent reads it, follows it most of the time. Then in a long session, it writes raw SQL in a service file. The reviewer catches it. Now it becomes a linter rule — any raw query outside a repository file triggers an error. The agent gets immediate feedback. That class of mistake stops happening.
Each promotion is an investment that pays off in every future session. One linter rule prevents one class of mistake forever. The harness compounds over time.
Fitness Functions: Sensors for Architecture
The escalation ladder ends at automated tests. For behavior, those are unit tests and integration tests. For architecture, they are fitness functions — automated checks that protect structural properties of the system.
A fitness function is any check that answers: “Does the code still respect this architectural decision?”
- “No module may import from another module’s internal files” — boundary fitness
- “Dependencies flow Presentation → Application → Domain, never backwards” — layering fitness
- “API schema changes must not break existing clients” — contract fitness
- “No direct database queries outside the repository layer” — data layer fitness
Architecture is not one thing. It spans multiple dimensions, and each needs its own fitness functions:
| Dimension | What it protects | Example |
|---|---|---|
| Structure | Module boundaries, layers, coupling | No cross-module internal imports |
| Contracts | API interfaces, schemas, type safety | Breaking change detection on schema updates |
| Data | Database schema, migrations | Destructive change detection, entity-schema drift |
| Maintainability | Code health, readability | Complexity limits, file size limits |
| Performance | Speed, resource usage | Bundle size budgets, query cost limits |
| Security | Secrets, auth, vulnerabilities | Secret scanning, auth enforcement on endpoints |
| Reliability | Error handling, resilience | Timeout enforcement, retry policies |
Most teams only have fitness functions for one or two dimensions — usually maintainability through linters. That leaves boundaries, contracts, data integrity, and security unprotected. A complete harness covers all dimensions critical to the project.
Fitness functions are not aspirational. They enforce what already works. Clean up a module, then add the fitness function to prevent regression. The function protects the investment. This is the “ratchet” pattern — quality goes up, never down.
What the Harness Can and Can’t Solve
Not every problem belongs to the harness. The harness targets the mechanical side — the mistakes that follow a pattern and can be caught by a rule.
| Harness can solve (accidental) | Humans must solve (essential) |
|---|---|
| Code follows the wrong pattern | Which pattern should exist |
| Import violates a module boundary | Where the boundary should be |
| Missing type annotation | What the domain model should look like |
| Test doesn’t exist for changed code | What behavior to test for |
| Naming convention violated | How to model the domain |
When the harness catches the accidental mistakes automatically, engineers spend their time on the essential ones — the part that actually creates value.
The Self-Improving Loop
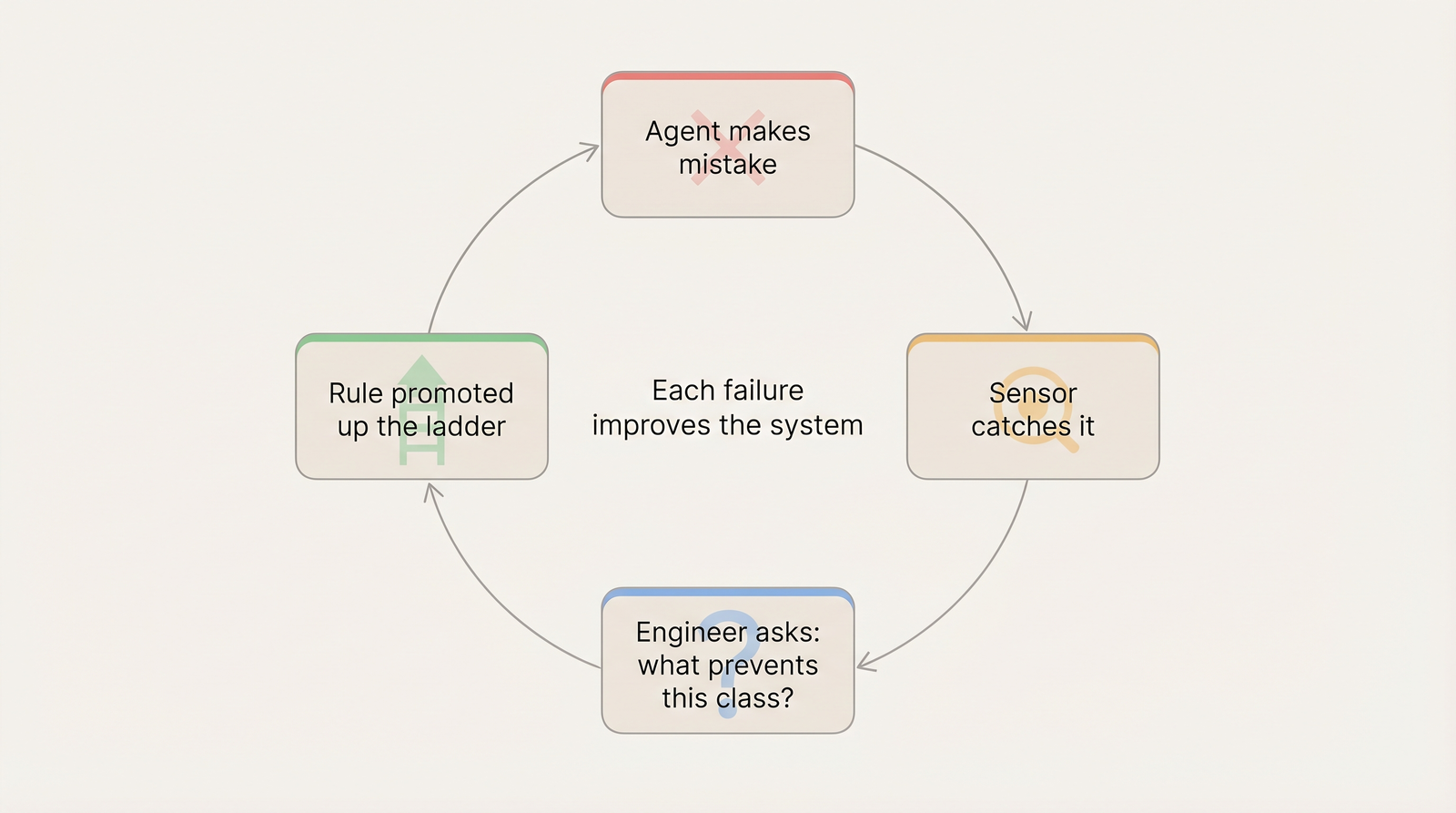
The harness is not static. It improves through a cycle.
Agent makes a mistake → Sensor catches it → Engineer asks: “What prevents this class of mistake?” → Rule promoted up the ladder → Next session: that mistake can’t happen
This is the core shift. When a mistake happens, the question is not “how do I fix this code?” The question is “what change to the environment prevents this from ever happening again?”
Each failure improves the system, not just the code.
When the rules are right, the code takes care of itself. When the rules are wrong, no amount of review keeps up with the speed of generation.
Circuit Breakers
When an agent can’t fix an error after multiple attempts, it should stop and escalate — not loop forever.
Fail. Retry. Fail. Retry. Fail. Escalate to a human.
This prevents wasted time and tokens. But more importantly, every escalation is a signal: the harness has a gap. The human fixes the immediate issue, then improves the harness so the same problem doesn’t happen again.
Circuit breakers turn agent failures into harness improvements.
The Engineer’s Evolving Role
When the harness handles verification, the engineer’s work shifts.
| Before | After |
|---|---|
| Write code | Design constraints and contracts |
| Review every line | Review rules and architectural decisions |
| Catch bugs in review | Encode prevention in automated checks |
| Fix individual mistakes | Fix the system that allows mistakes |
In my experience, the teams that get stuck have invested heavily in guides — dozens of rule files, detailed documentation, architecture conventions. The guides help. But every PR still requires full manual review because nothing catches violations automatically. The guides tell the agent what to do. Nothing tells it when it did something wrong.
Adding sensors to the loop changes the dynamic. The agent self-corrects before a human sees the output. Review shifts from catching syntax and structure mistakes to verifying intent and design decisions. The human reviews the thinking. The harness reviews the code.
Where to Start
Most teams already have the pieces. Linters, type checkers, test suites — they exist in the repository and run in CI. The gap is that none of them are connected to the agent’s working loop.
A practical starting point:
- Audit the gap. List your guides (rule files, documentation, conventions) and your sensors (what runs automatically when the agent acts). Most teams find the sensor column is empty.
- Wire existing tools into the agent loop. Linter after every edit. Type checker incrementally. Related tests before the task is done. No new tools — just new connections.
- Track what the agent fails at. Every mistake the agent makes and a human catches in review is a missing sensor. Log them.
- Promote rules up the ladder. When a documented rule gets violated more than once, encode it as a linter rule or a fitness function. Each promotion is permanent.
- Add circuit breakers. When the agent can’t fix something after three attempts, it should escalate instead of looping. Every escalation tells you where the harness needs work.
The harness is not a one-time project. It grows with the codebase. Each failure becomes a new rule. Each rule prevents a class of mistakes forever. The teams that compound these improvements over time are the ones where AI agents actually deliver on the productivity promise.
References
- Harness Engineering — Martin Fowler. The Agent = Model + Harness framework, feedforward (guides) vs feedback (sensors), computational vs inferential controls.
- Building Evolutionary Architectures — Neal Ford, 2017. Fitness functions as architectural tests, architectural dimensions, guided incremental change.
- Harness Engineering with Codex — OpenAI. Escalation ladder, lint messages as remediation instructions, circuit breakers for agent loops.