Evolving a TypeScript Backend for AI-Generated Code
About 50% of our backend code is now AI-generated. Some teams reach 90%. AI writes code faster than any human can review. That speed is valuable — but only if the output is trustworthy.
The question we had to answer: how do you trust code you did not write and cannot review line by line?
The Problem with Speed
We started our backend in 2021 with a modular monolithic architecture. One codebase, separate modules, everything deployed together. A small team, moving fast. Engineers had freedom to code in their own style. Speed was more important than consistency.
├── modules/
│ ├── module-A/
│ ├── module-B/
│ └── ...
└── server.tsThat worked for the MVP. Then the product grew into multiple products. One backend team became several. And AI code assistants entered the daily workflow.
AI amplifies whatever patterns exist in the codebase. When the structure was unclear, AI copied unclear patterns — faster. Modules called each other freely. There were no real boundaries between products. One big deployment for everything. The problems we already had got worse at machine speed.
Manual review does not scale when half the code is machine-generated. We needed the architecture itself to enforce correctness.
Architecture as the Safety Net
The answer was not to slow down AI. The answer was to make the codebase so structured that AI-generated code is safe by default.
Stronger Boundaries: Monorepo
We migrated from a modular monolith to a TypeScript monorepo. Each product became its own deployable app. Shared logic moved to /packages. Clear import rules prevent unwanted coupling between apps.
├── apps/
│ ├── app-A/
│ └── app-B/
└── packages/
├── package-A/
├── package-B/
└── core/The structure became the documentation. AI can see the entire system — apps, packages, boundaries. Code generation becomes predictable because the rules are visible in the file system itself.
Clear Layers: Clean Architecture
Inside each app and package, we follow Clean Architecture with four layers: Domain (business logic), Application (use cases), Infrastructure (DB, APIs, external services), and Presentation (GraphQL/HTTP entrypoints).
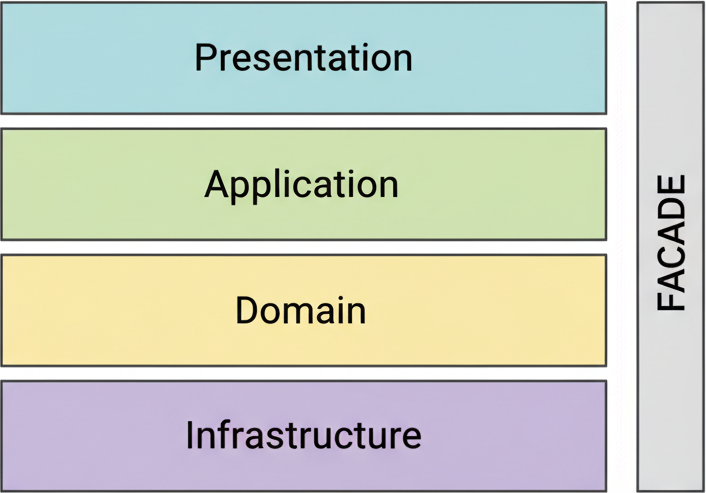
Each layer has one purpose. AI knows exactly where to put new code. Changes in one layer do not break other layers. This separation is critical when code is generated quickly — side effects are the biggest risk with fast generation.
Contracts as Code
This is the core of the approach. Contracts define the shape of the system before any implementation exists. When contracts are clear, both humans and AI know what to build. Implementation becomes predictable.
We use five types of contracts: TypeScript types for domain models, facades for module communication, GraphQL schemas for API contracts, Prisma schemas for database structure, and Zod for runtime validation.
The facade pattern is the most important boundary:
export interface BookingFacade {
create(input: CreateBookingInput): Promise<Booking>;
getById(id: BookingId): Promise<Booking | null>;
}Every module exposes only a facade. Modules do not know about each other’s internal code. If the contracts are respected, the implementation details matter less. AI generates services, resolvers, and tests based on these shapes. The contract guarantees the output fits the system.
TypeScript types model the domain. GraphQL schemas define what clients can request. Prisma schemas generate typed database clients. Zod validates inputs at runtime. Each contract serves a different boundary, but the principle is the same: define the shape first, then generate the code.
Testing as Trust
Contracts give shape. Architecture gives structure. Testing gives trust.
Each architectural layer has its own testing focus. Domain tests verify business logic. Application tests verify use-case integration. Presentation tests verify GraphQL input/output end-to-end. Each layer defines what to mock and what to test.
AI code agents work layer by layer. After generating each layer, they run tests before moving to the next. Build errors and linter warnings are caught immediately. AI fixes them automatically.
After all code is generated, AI review agents verify architecture rules, import boundaries, and test coverage. Humans review design and intent — not every line of code.
The Self-Improving Loop
When AI-generated code fails, we do not patch it manually. We improve the rule, the contract, or the schema — and generate again.
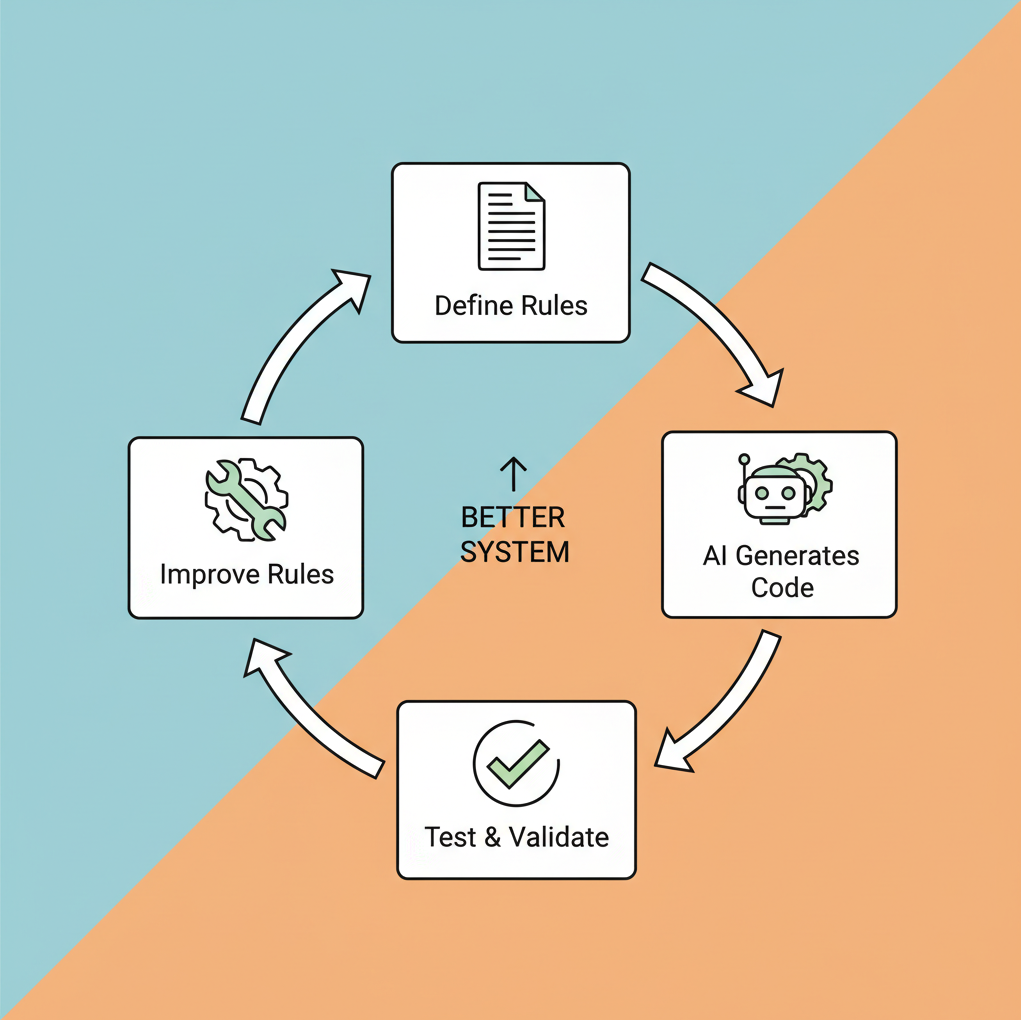
Each failure improves the system, not just the code. Better contracts produce better generated code next time. Better architecture rules prevent the same class of errors from appearing again. The system gets smarter with every iteration.
This is the real shift. Engineers are moving from writing code to designing architecture, rules, and requirements. AI handles the implementation. The engineer’s job is to make the rules so clear that the generated output is correct by construction.
What We Learned
We are still migrating — parts of our system follow the new architecture, others are being aligned gradually. But the direction is clear.
The combination of TypeScript, clean architecture, and contracts as code is already improving speed, quality, and consistency. This is not about rewriting everything at once. Evolution is safer than revolution. Keep what works. Change what does not. Step by step.
The best practice I have found is to invest most of the time in defining the right abstraction rules — not in reviewing generated code. When the rules are right, the code takes care of itself. When the rules are wrong, no amount of review will keep up with the speed of generation.
The backend that works in the AI era is not the one with the best code. It is the one with the clearest boundaries.